From ABBYY to Gemini: How we rebuilt receipt recognition with AI
For the past 6+ years, I’ve been building and evolving a product Nettlønn by ECIT that helps employees report business expenses using a mobile app — and helps companies review, approve, and manage those reports efficiently.
by Yaroslav Nychka, Software Developer | Ruby Developer at Innocode
For the past 6+ years, I’ve been building and evolving a product Nettlønn by ECIT that helps employees report business expenses using a mobile app — and helps companies review, approve, and manage those reports efficiently.
An employee might snap a photo of a receipt at a restaurant or parking lot, right inside the app. No need to collect paper slips or print PDFs. Digital receipts — like flight bookings or Uber ride invoices — can simply be forwarded via email and automatically processed.
Once a receipt is captured, our backend analyzes it and pre-fills key fields like amount, currency, merchant, and date. Employees no longer need to manually type everything — they just review and submit.
On the other side, accountants and managers can use a web backoffice or mobile app to review, approve, or reject expenses with a few taps.
The ideal flow is simple: capture and send. No manual typing, no form-filling — just a quick review. That’s what we’ve been aiming for from day one.
But at the heart of it all lies the hardest — and most important — challenge: understanding receipts.
This isn’t just about recognizing text. It’s about extracting the right total amount, the correct VAT, the true merchant name — reliably, across every document format, language, and layout. That data goes directly to finance teams and affects reimbursements, compliance, and internal audits.
If something’s off — even slightly — an expense can be rejected. That’s frustrating for the employee who did everything right. And let’s face it: under pressure, even finance teams make mistakes. Getting this right isn’t optional — it’s essential.
And it’s where we made our biggest leap: from brittle regex rules and aging OCR engines… to real AI that understands documents like a human.
Inheriting a System You Can’t Touch: Locked into ABBYY and a Forest of Unmanageable Regex
When I joined the project in 2019, the platform had already been using ABBYY Cloud OCR for several years — and to be clear, ABBYY wasn’t the problem.
The OCR engine worked fairly well. It could extract raw text and structured data from scanned receipts, invoices, and PDFs. Most documents were processed in under a minute, though some took up to two — and large PDFs could fail or time out.
But overall, it did its job, the real problem was what had been built around it.
To get useful data from a single image, the system had to:
- Send the image to ABBYY for raw text recognition.
- Then make a second API call to fetch ABBYY’s structured XML.
This wasn’t just inefficient — it doubled the cost, added latency, and introduced more points of failure. Sometimes the first request succeeded and the second failed, resulting in incomplete processing or silent errors.
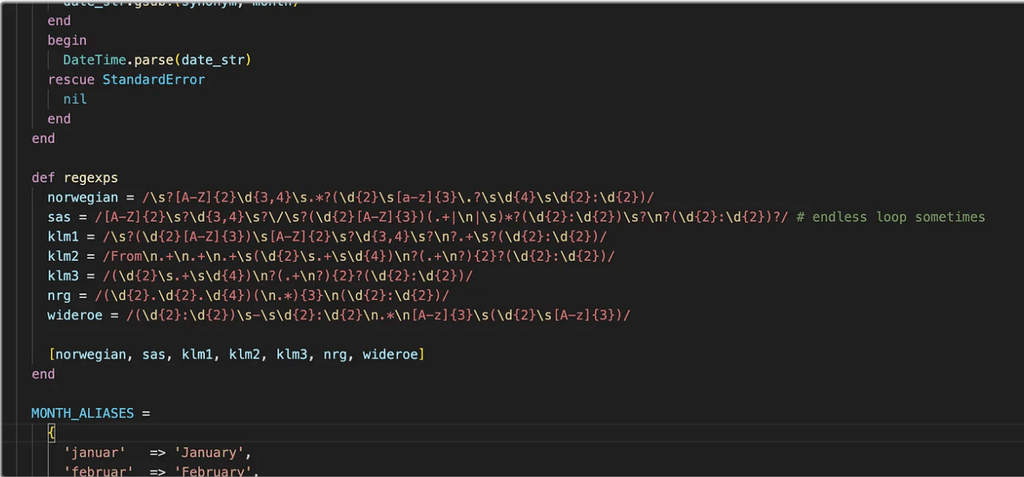
Worse, the downstream system — dozens of regex rules and custom parsers — depended not just on ABBYY’s data, but on the exact shape of its legacy XML.
What I inherited was a system where:
Regex logic was tightly coupled to ABBYY’s XML.
- Parsing logic was duplicated, inconsistent, and undocumented.
- There was no abstraction between OCR and business logic.
- No one truly understood how changes would affect the rest of the pipeline.
It became clear why prior attempts to upgrade to newer ABBYY APIs had failed. Even minor differences in XML structure broke the whole chain. I tried eliminating the second request — to reduce costs and simplify the flow — but the entire chain was too brittle. A developer before me tried as well — and left shortly after.
We weren’t just using ABBYY — we were entirely dependent on its quirks.
And that came at a cost.
Over time, this architecture did more than slow us down — it quietly eroded morale:
- Developers became afraid to touch the OCR logic.
- Fixing one bug often broke something else.
- Failures were silent — receipts would go unprocessed, and no one could explain why.
- Customer trust declined.
- The team shrank. Eventually, the product was sold to a new company.
Looking back, the warning signs were everywhere.
The regex layer had become the core of the product — but it was fragile, undocumented, and unsafe to evolve. The system didn’t just resist change — it punished attempts to improve.
Important to note: ABBYY OCR and regex aren’t inherently bad.
We still use regex today — for example, to recognize file types in forwarded emails before routing them to AI pipelines.
The issue wasn’t the tools. It was the fragile architecture that glued them together.
There was no separation between OCR output and business logic. Parsing rules were hardcoded to ABBYY’s XML format — with no fallback and no plan to evolve.
In the end, we weren’t just dependent on ABBYY — we were locked in to an outdated version, unable to upgrade without risking regressions across dozens of brittle parsing rules.
What started as a clever shortcut had become a high-risk bottleneck that frustrated developers, confused users, and blocked progress.
That’s when we knew: it was time to find a better way.
Instead of ripping everything out overnight, we took a measured approach — and that’s where Google Document AI came in.
Alongside the backend evolution, we rewrote the entire original Travis app from scratch — it was poorly integrated with the backend. The new app is written in Dart/Flutter and far more cohesive. At the same time, we developed a new API, consistent across web and mobile. That meant reorganizing the architecture: a unified backend API, serving both platforms smoothly. As I reflect, so much has happened over these five years I’ve been part of this — on all fronts, from UI to infrastructure.

Breaking Free: Building an Adapter Layer
Before we could even think about replacing ABBYY, we had to untangle ourselves from it.
The legacy system was tightly coupled to ABBYY — regex rules, parsers, and downstream business logic all depended on its exact structure. Swapping out the OCR engine without preparation would have broken the entire pipeline.
To make change possible, I introduced an adapter layer — wrapping all interactions with ABBYY behind a single input/output interface. This gave us a clean boundary between the OCR engine and the rest of the system — for the first time, we could replace the engine without rewriting everything else.
With that abstraction in place, I implemented a Google Document AI adapter using the same interface — so ABBYY and Document AI could be swapped in and out seamlessly.
Why Google Document AI?
We chose Google Document AI for three main reasons:
- Infrastructure fit — even though our customer receipts were stored on AWS, the rest of the platform was running on Google Cloud, which made integration and deployment smoother.
- Pretrained intelligence — Document AI offered out-of-the-box processors for receipts and invoices, giving us a strong baseline.
- Secure, controlled training — a key factor was the ability to train models without sending sensitive documents to unknown third-party services. With Google Document AI, we could upload real receipts, label them ourselves in the UI, and keep everything within a trusted cloud ecosystem.
But the biggest benefit was custom processors.
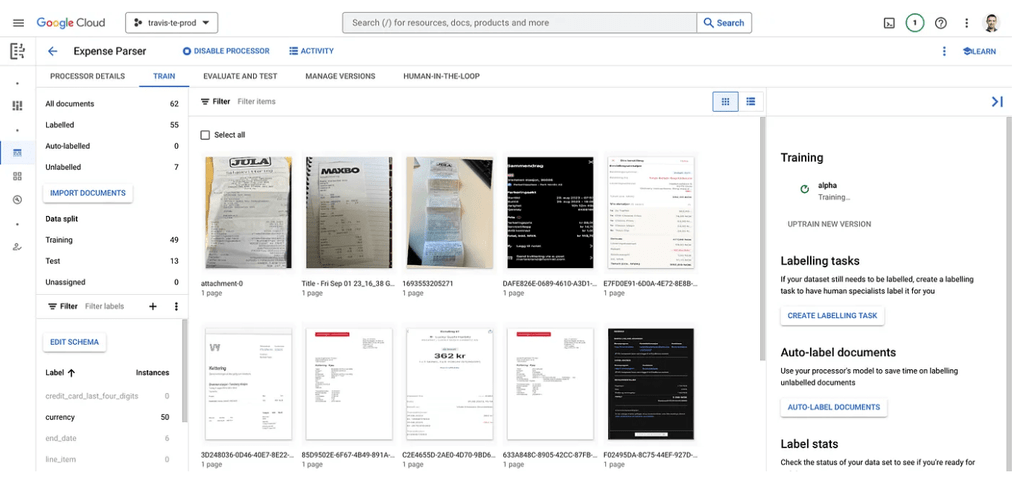
We could train Document AI on real-world receipts by manually labeling key fields using their training UI. Yes, it was time-consuming and yes, it required a human in the loop. But it worked. Over time, accuracy improved — and we gained control we never had with ABBYY.
Parallel Pipelines, Real-Time Comparison
At this point, we had two OCR engines running behind the same interface.
But switching engines blindly wasn’t an option. To avoid regressions and safely transition to Document AI, I built a parallel pipeline runner: every document processed by ABBYY was also silently sent to Document AI.
We logged both outputs and diffed the results — measuring accuracy field by field.
This phase was critical. It gave us the confidence to flip the switch when the time was right — knowing we weren’t risking live customer data or degrading quality.
Measuring Accuracy: Field-by-Field, Receipt-by-Receipt
To go beyond logs and diffs, I built an internal UI that displayed each receipt side by side — one parsed by ABBYY, the other by Google Document AI.
This wasn’t just for show. It allowed our admin team to manually label the correct values field-by-field, helping us answer a critical question: which engine actually got it right?
With this feedback loop in place, I built a dashboard to track accuracy scores across both engines. We could now see — in real time — how ABBYY and Document AI were performing across key fields like merchant, total, currency, and date.
Our goal was simple: Document AI had to match ABBYY — or do slightly better — before we’d even consider flipping the switch.
To test this, we ran dozens of real-world receipts through the pipeline and had the team label ground truth data. For every document, the system calculated recognition accuracy for both providers. This gave us something more powerful than gut feeling: a statistically meaningful quality score, backed by real data.
It took a couple of weeks of labeling and iteration. But that investment paid off — not just in accuracy, but in confidence.
By the end of the evaluation, we weren’t debating opinions. We had charts, scores, and documented wins. It wasn’t just that Document AI felt better — we knew it was.
Safe Rollout and the End of ABBYY
Going live didn’t mean flipping a global switch.
We designed the transition to be granular and reversible, with the ability to choose the OCR engine on a per-company basis. This gave us the flexibility to run real production tests while minimizing risk.
We started with a test company used by the internal team and stakeholders. Once confidence grew, we enabled Document AI for a real customer account — with their consent — to gather field data and early feedback.
If anything looked off, we could instantly revert that company back to ABBYY — the switch was live and seamless.
This company-level rollout strategy let us move forward safely while continuously validating our assumptions in the real world.
To keep everyone aligned — from engineers to stakeholders — I built a live dashboard that showed how each OCR provider was performing in real-time.
For each engine, we tracked expense recognition accuracy as a percentage, based on manually verified samples. The UI made it easy to see which engine was primary and how they compared side-by-side.
We updated the stats regularly and even included a quick switch button, so we could change the primary OCR provider at any time — per environment or company. This transparency helped everyone understand why we were moving to Document AI — not just because it was newer, but because it was provably better.
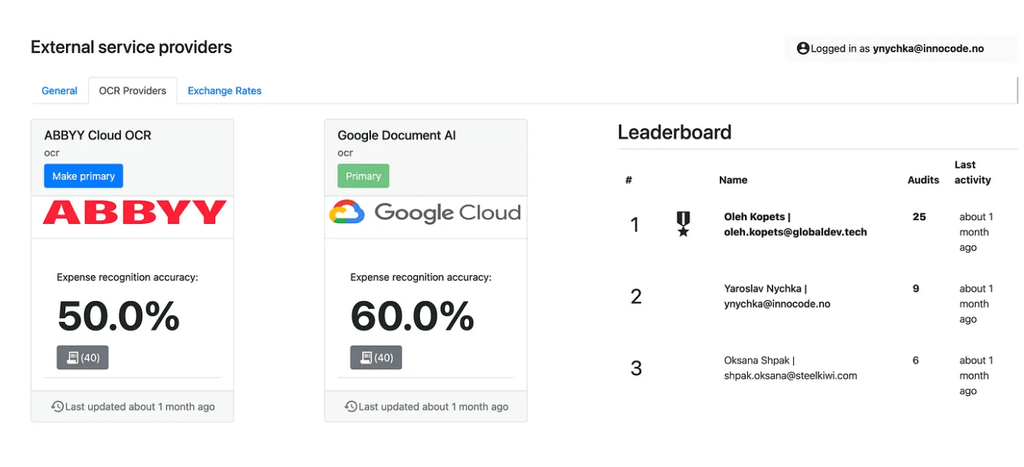
After weeks of testing, tuning, and measuring field-by-field accuracy, the numbers spoke clearly: Google Document AI was outperforming ABBYY — and not just slightly.
We had everything in place:
- A company-level switcher to run safe tests.
- A fallback to ABBYY in case of emergencies.
- Real-world data from internal teams and stakeholders.
- A live dashboard proving superior recognition accuracy.
When we hit our target — Google consistently beating ABBYY on real documents — we didn’t hesitate.
We pressed a single button. And we never looked back.
In that moment, we flipped all customers to Google Document AI — instantly and confidently.
It was more than just a technical switch. It was a moment of freedom. We had finally broken the chains of ABBYY’s XML jungle, regex nightmares, and fragile post-processing.
But that moment wasn’t the end — it was a new beginning.
Replacing ABBYY with Google Document AI was a turning point, but we weren’t done.
Document AI gave us solid accuracy, but its predefined fields and limited flexibility couldn’t keep up with our evolving needs.
The real blockers?
- Speed: up to 10 seconds per receipt was too slow for a smooth user experience.
- Training overhead: Teaching the model meant uploading receipts, labeling every field, and repeating — a huge manual effort.
With our system already decoupled from any single provider, we went looking for the next leap forward. That’s when we turned to LLMs like ChatGPT and Gemini — faster, more adaptable, and easier to improve on the fly.
Much of this evolution happened amid wartime conditions. Staying focused in such times is extraordinary — my heart goes out to our colleagues in Ukraine. For many, having meaningful work served as a respite from the daily horrors of the frontlines. Though they belong to different tech companies, our Ukrainian team felt united in purpose — it simply happened that way during parallel discussions with multiple ECIT partners.
Goodbye Labeling, Hello Prompts: How Gemini Changed Everything
When evaluating prompt-driven AI options, we considered ChatGPT but ultimately chose Gemini for several critical reasons.
Being a Google product, Gemini offered stronger security and compliance for handling sensitive customer receipts — a must for protecting user data. Its pricing model was more cost-effective at scale, allowing us to process thousands of receipts without breaking the budget.
Speed was another big factor: Gemini responded in just a couple of seconds, compared to 9–12 seconds we experienced with Google Document AI. This drastically improved our pipeline’s throughput and iteration speed.
Most importantly, Gemini’s prompt-driven approach let us skip time-consuming manual labeling. By crafting prompts instead, we achieved significantly higher recognition accuracy with less overhead.
In short, Gemini perfectly balanced security, cost, speed, and accuracy — making it the clear choice for our evolving receipt recognition system.
Our transition to Gemini was smoother than ever — no post-processing rewrites, no human-in-the-loop layer.
The system was ready: we just implemented a new adapter, grew confidence with data, and flipped the switch.
Now, we’re going even further.
Building a Prompt Playground: Iterate Faster, Improve Smarter
I built an internal tool something like prompt playground to write and test prompt versions against a growing library of real receipts — our “gold standards.”
Each test run gave direct feedback: how well did Gemini extract key fields.
We’re now expanding that tool to allow admins to upload any receipt, experiment with new prompts, and monitor extraction quality in real time.
Empowered by AI and real-time prompt testing, we’re building toward a future where we can improve receipt recognition on the fly — without deployments, just fast, flexible evolution driven by smarter prompts.
Final thoughts and some personal reflextions.
When I joined the project in 2019, ABBYY took anywhere from 30 to 120 seconds to process a receipt — and it took us several years before we could implement Google Document AI and start meaningfully improving recognition quality.
Now, with Gemini, processing happens in just a couple of seconds — a dramatic speedup that has transformed user experience and boosted operational efficiency.
The next big step, as I see it, is building a self-optimizing engine — one that learns from every receipt in real time, adapts its prompts automatically, and improves recognition without human intervention. No redeployments. No manual tuning. Just an intelligent system that gets smarter with every document — evolving on its own to deliver the best possible experience.
This journey has truly taught me that modern AI isn’t just about swapping tools — it’s about building systems designed for change. Whether you’re working with regex, classic OCR, or cutting-edge AI, your architecture must be adaptable and ready to evolve.
Without that flexibility, technical debt can quickly bury even the best plans.
If you’re tackling complex document understanding, focus on creating resilient, maintainable systems first — the right foundation unlocks real innovation and lasting business value.
Innocode (Yulieta by Innocode) has been a steadfast partner throughout, supporting not only backend development but also QA (thanks to Iryna Demkiv), architecture, and ongoing consultation. I look forward to many more years of fruitful collaboration with Innocode.

AI, people & innovation
We dive into and challenge some common perceptions about AI. We explore practical tips and tricks that you can apply to both your work and daily life. See the full webinar here.

Airmine
Airmine collaborated with Yulieta by Innocode to scale their technical capabilities and streamline development. This partnership provided access to expertise in Flutter and React, driving innovation in pollen risk forecasting.